最近公司有老员工离职,准备让我接手他的工作,但是一眼看过去,代码规范和版本管理实在是不忍直视,忍不住在这里吐槽一下,同时也提醒自己注意这些问题,尽量写出优美的代码,方便自己也方便别人。
公司的工作代码是C语言,因为每个公司都有自己的一套风格,在代码风格方面不做评价,只看看代码规范中的一些奇葩问题吧:
(1)单个文件过大,单个文件长度甚至超过20000行!导致寻找函数困难,文件过大也导致垃圾代码一直沉淀下来,达到目前这一叹为观止的规模。
(2)函数名过长,参数过多:最长函数名长达63个字符,参数达到37个!我的22寸的显示器的宽度都不足以完整地显示一行代码,要拖动滚动条。
(3)函数命令混乱,比如,充斥着大量的类似于 “WriteBinData()”、 “WriteBinData2()” 和 “WriteBinData_New()” 这类命名方式,根本让人无法区分这些函数。
(4)代码重复率高,常常出现两个几乎一致的几百行的函数,其中差别就在于几个变量的不同。他们并没有将不变的地方抽出形成函数,而是直接进行复制粘贴,导致最后代码重复率惨不忍睹,而且也带来的是维护工作量相应增加。
(5)无节制地使用宏,导致代码中到处都是被宏分割的片段,根本无法理清楚逻辑。比如下面这种:
//////
#if 1
...
#else
...
#endif
//////
#ifdef XXX
...
#else
...
#endif
(6)文件长,我认了;函数名混乱,我也认了;宏多,逻辑好歹能看出来,前提是,得有注释来解释这些。最关键的一点:所有函数、代码、逻辑、文件无任何注释!算法本身就比较难懂,而且对于优化过的算法来说,没有注释就是一个噩梦,作者都看不懂,更何况后续维护的兄弟呢。
其他一些问题,类似于:函数声明夹杂在.h文件和.c文件中,变量命名不规范等等,我就不一一列举了,实际上,我们公司是有完整的代码规范的,如果遵守了这些规范,很大程度上就能避免以上这些问题。刚进入公司的时候,我曾经问过同事,为什么明显违反规范的代码还能提交到代码库来,得到的答案是:“我们做算法的,不太注意这些。”我哑口无言。组里没有代码审查这一说法,如果工程师不严格遵守代码规范,最后得到的只能是一坨“Shit”。目前这份代码才三年多时间,已经成功刷新了我对烂代码的认识。
以前在思科实习的时候,维护过一个有着10年历史,上百万行的Java API,当时还跟导师Simon抱怨说:“这代码太乱了!” Simon很不好意思跟我说:“你来这里这么久,最遗憾的是没让你看过漂亮的代码,好代码看多了,你也就能写出好代码。” 再后来跟Kent聊到代码质量这事,Kent的原话是这样的:“随着时间和代码量的增长,代码质量会不可避免地下降。但你要相信,在最开始的时候,每个工程师都在想怎样把代码写得清晰和易于维护。”
现在看来,思科的那份代码经过10年,其中多次交接还能被很好地维护,工程师为了那份代码已经是很努力的了。最少,让我相信了Kent说的:“在最开始的时候,每个工程师都在想怎样把代码写得清晰和易于维护。”
关于如何写出简洁、规范、有效的代码,要一一列举出来非常的长,自己水平不够,不敢献丑,推荐一本书:Clean Code。
公司代码版本控制采用的SVN,一般的代码分支规则是这样的:建立三个目录,名字分别为trunk,branches和tags:
- /trunk 存放最新的特性开发代码,当系统达到一个较大的里程碑版本的发布要求时,特别是新版本包含了非向下兼容代码时,应在 /branches 下面建立一个相应的分支,以便维护旧版本代码。
- /tags 目录用于标记版本,每次系统版本号的提升不论大小都应该在 /tags 里记录。
- /branches 里的分支发现的 bug 均应该反向移植到影响的分支中,/branches 里的分支视情况而定,一般只维护最近稳定版本分支。
话是这么讲的,新员工培训也是这么教的,可是我见到我们组的SVN的根目录是这样的:
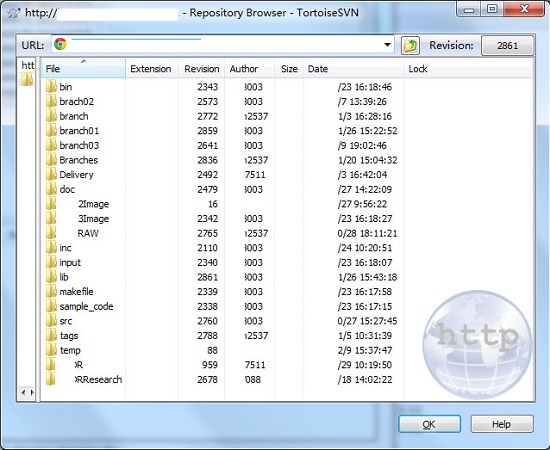
其中存在temp、bin,无命名意义的branch/01/02/03,文件夹内还有很多的临时编译文件。让人难以忍受的是,看着有多个branch(虽然难看了点),其实完全不是用来区分不同厂家的递交版本的。组里工程师区分版本的方法依然是查看commit log,根据log来提取不同的版本。是的,没看错,根据log来区分同一个branch里面什么时候提交的代码是给A厂的,哪些是给B厂的,即使多个版本的代码没有任何merge的可能性。
我只能用一幅图来表达我的心情:

乘着老大出门,在我的努力下,该删的删,该移的移,该开branch的开branch,终于把根目录精简到了只剩4个文件夹。PS:动了老大的代码,不知道他回来会不会把我狂骂一顿。
吐槽完毕,来讲点实际的。说到代码版本控制,推荐一下最新的Git。跟SVN相比,最大的区别是它在本地也保存了一个代码库,这样可以离线工作,首先将代码提交到本地仓库,联网之后再同步到服务器端。代码托管网站 Github 和 Bitbucket 都支持Git版本控制,并提供客户端。
如果觉得branch太多,不好管理,那么试一试Git-Flow吧。为了管理多个branch,有人开发出了Git-Flow这套模型,简单来说,将branch分为两个主要分支,三个支援型分支:
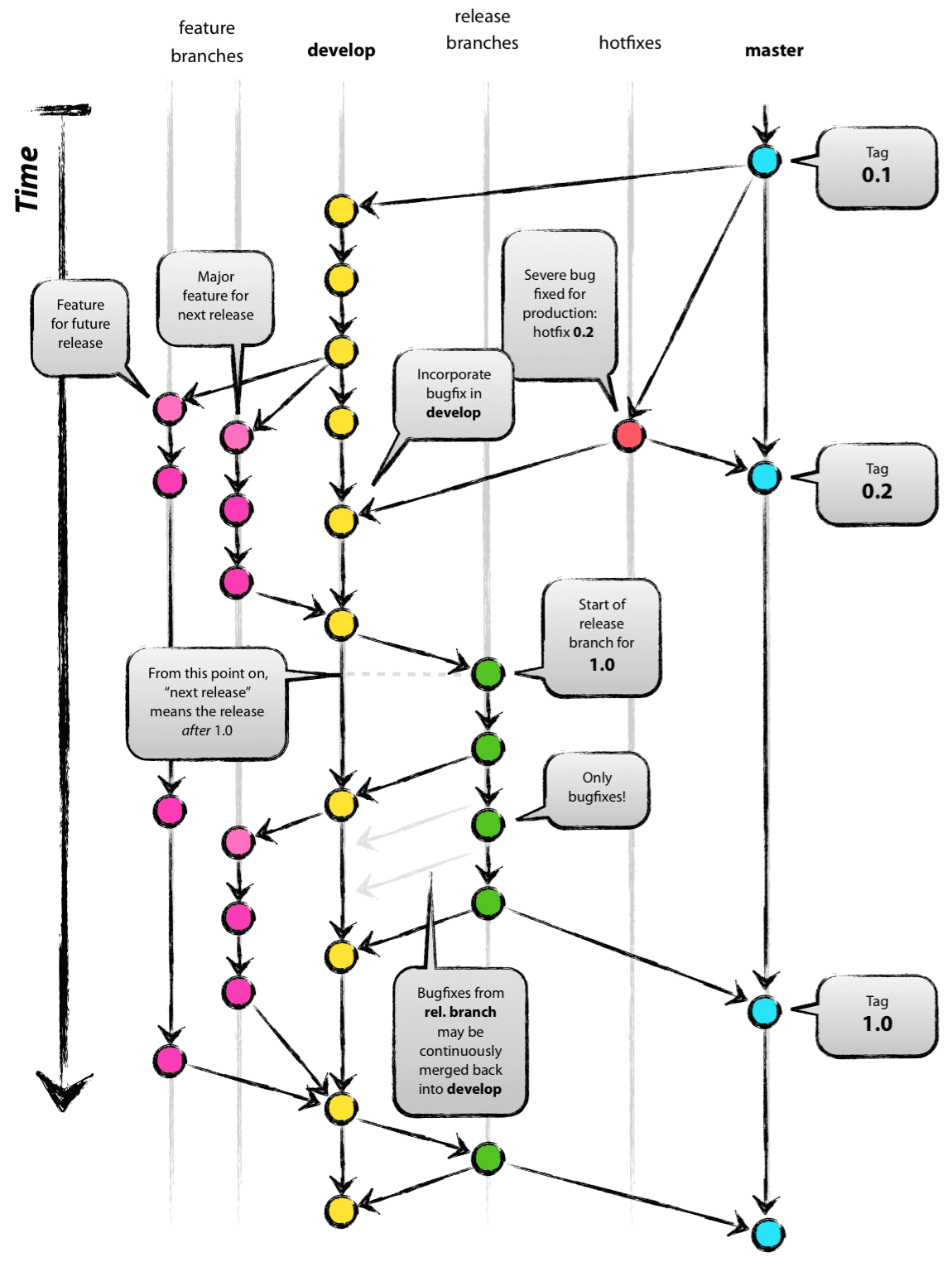
两个主要分支:
- master: 永远处在 production-ready 状态。
- develop: 最新的下次发布开发状态。
三个支援型分支:
- Feature branches: 开发新功能都从 develop 分支出来,完成后 merge 回 develop。
- Release branches: 准备要 release 的版本,只修复 bugs。从 develop 分支出来,完成后 merge 回 master 和 develop。
- Hotfix branches: 等不及 release 版本就必须马上修改 master 赶着上线的情況。会从 master 分支出来,完成后 merge 回 master 和 develop。
此外,推荐一个软件SourceTree,是Bitbucket母公司Atlassian开发出来的代码管理客户端,同时也支持Github,并且里面自带了Git-Flow流程,能够方便地将当前的代码转到Git-Flow上。我目前使用的就是它啦。
[1] A successful Git branching model
[2] git-flow 备忘清单
[3] SourceTree http://www.sourcetreeapp.com/
[4] bitbucket https://bitbucket.org/
Last update: 2014-12-05